License : Creative Commons Attribution 4.0 International (CC BY-NC-SA 4.0)
Copyright :
Hervé Frezza-Buet,
CentraleSupelec
Last modified : February 15, 2024 11:13
Link to the source : index.md
Table of contents
Ensemble Methods lecture materials
Boosting
We can use any week predictor and overcome inductive bias.
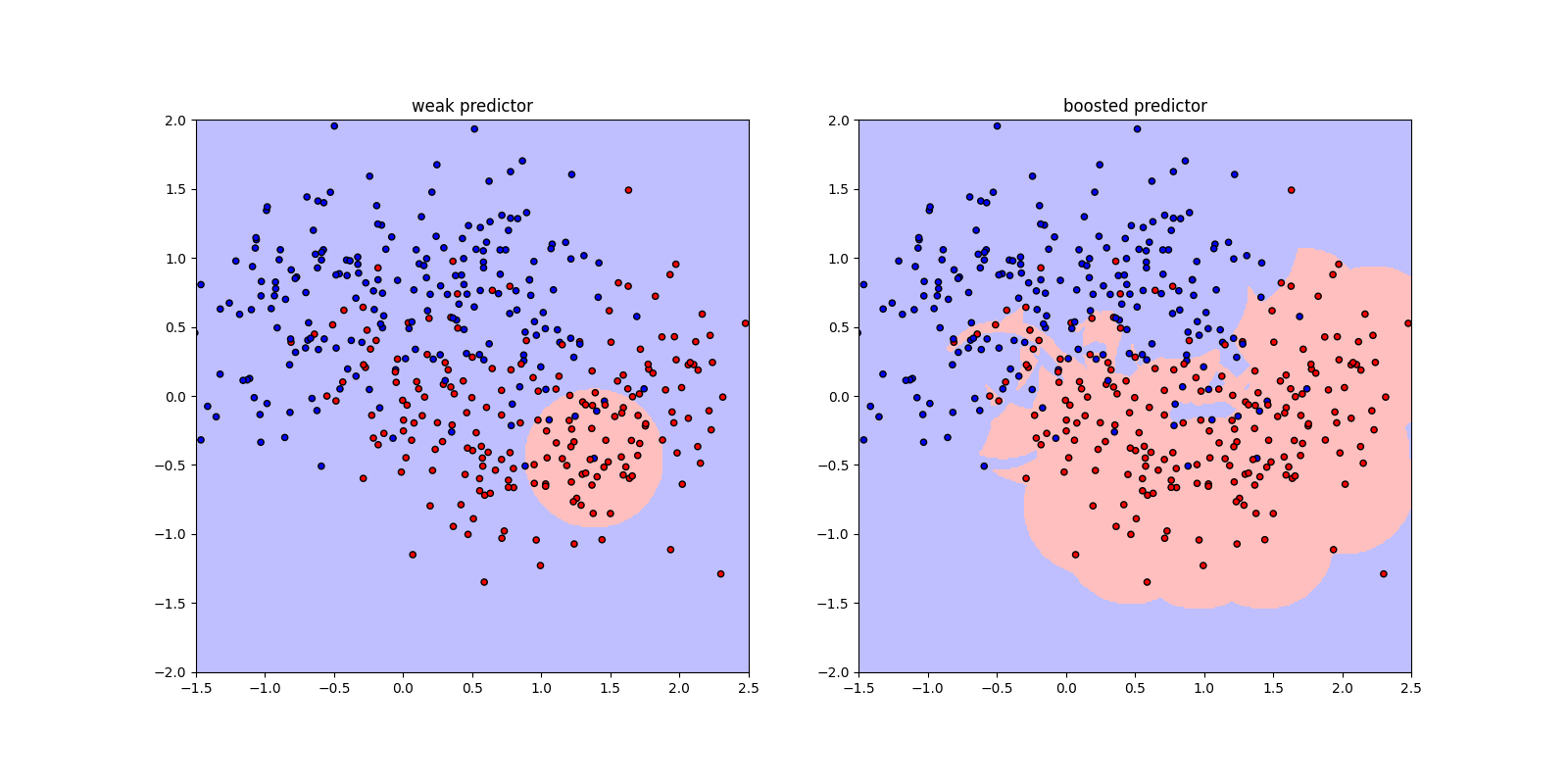
This is how it is built up.
Implementing boosting is not that difficult.
import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets
import os
class DiskLearner:
def __init__(self, radius):
self.r2 = radius*radius
self.center = None
self.y_in = 1 # The label of samples inside the disk.
self.y_out = -1 # The label of samples outside the disk.
def inside(self, center, X):
"""
Returs wether each sample in X is in the disk centered at
center.
"""
dist2 = np.sum((X - center)**2, axis=1)
return (dist2 <= self.r2).astype(float)*2-1.0
def ___in_pos_risk(self, center, X, y, wgts, sum_wgts):
"""
Returns the weighted risk if we consider a prediction 1
inside the disk.
"""
inner = self.inside(center, X)
return np.sum((inner * y < 0) * wgts) / sum_wgts
def ___in_neg_risk(self, center, X, y, wgts, sum_wgts):
"""
Returns the weighted risk if we consider a prediction 1
ouside the disk.
"""
inner = self.inside(center, X)
return np.sum((inner * y > 0) * wgts) / sum_wgts
def fit(self, X, y, wgts=None):
"""
Finds among the centers in X the one with the minimal
empirical risk. Both cases (return 1 inside, return 1
outside) are considered and (self.y_in, self.y_out) is
set to (-1, 1) or (1, -1) accordingly.
"""
center_min = None
rmin = 100.0
if wgts is None :
wgts = np.ones(len(X), dtype=int)
sum_wgts = np.sum(wgts)
if sum_wgts <= 0 :
sum_wgts = 1.0
for x in X :
r = self.___in_pos_risk(x, X, y, wgts, sum_wgts)
if r < rmin :
rmin, self.y_in, self.y_out, self.center = r, 1, -1, x
r = self.___in_neg_risk(x, X, y, wgts, sum_wgts)
if r < rmin :
rmin, self.y_in, self.y_out, self.center = r, -1, 1, x
return rmin
def predict(self, X, useless_arg = None):
y = np.full(len(X), self.y_out)
dist2 = np.sum((X - self.center)**2, axis=1)
y[dist2 <= self.r2] = self.y_in
return y
def color_of_label(l) :
if l >= 0 :
return 'red'
else:
return 'blue'
def plot_samples(ax, X, y, color_of_label = color_of_label):
size = 20
colors = [color_of_label(l) for l in y]
ax.scatter(X[...,0], X[...,1], s=size, c=colors, edgecolors='black', zorder=-1)
def plot_partition(ax, classifier, xlim, ylim, colors, bound=None):
nb_steps = 300
xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], nb_steps),
np.linspace(ylim[0], ylim[1], nb_steps))
Z = classifier.predict(np.c_[xx.ravel(), yy.ravel()], bound) # np.c[[x,x,...], [y,y,...] = [(x,y), (x,y), ...]
Z = Z.reshape(xx.shape)
levels = [-1.5, 0, 1.5]
ax.contourf(xx, yy , Z, levels, colors=colors, zorder=-3)
class DiskBooster:
def __init__(self, nb, radius):
self.nb = nb
self.radius = radius
self.preds = []
def boost(self, X, y, weights):
p = DiskLearner(self.radius)
e = p.fit(X, y, weights)
alpha = .5*np.log((1-e)/e)
yy = p.predict(X)
weights[yy == y] *= np.exp(-alpha)
weights[yy != y] *= np.exp(alpha)
weights *= (1./np.sum(weights))
self.preds.append((alpha, p))
def fit(self, X, y) :
self.preds = []
w = np.ones(len(X), dtype=float)/len(X)
for i in range(self.nb):
self.boost(X, y, w)
def unthresholded_predict(self, X, last_pred=None):
yy = np.zeros(len(X))
if last_pred is None:
bound_pred = len(self.preds)
else:
bound_pred = last_pred
for (a, p) in self.preds[:bound_pred]:
yy += a * p.predict(X)
return yy
def predict(self, X, last_pred=None) :
y = np.full(len(X), 1)
y[self.unthresholded_predict(X, last_pred) < 0] = -1
return y
def plot_unthresholded_values(ax, classifier, xlim, ylim, bound=None):
nb_steps = 300
xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], nb_steps),
np.linspace(ylim[0], ylim[1], nb_steps))
Z = classifier.unthresholded_predict(np.c_[xx.ravel(), yy.ravel()], bound) # np.c[[x,x,...], [y,y,...] = [(x,y), (x,y), ...]
Z = Z.reshape(xx.shape)
scale = np.max(np.abs(Z))
Z = Z / scale
ax.imshow(Z, cmap='bwr', vmin=-1, vmax=1, extent = (xlim[0], xlim[1], ylim[1], ylim[0]), zorder=-3)
X, y = sklearn.datasets.make_moons(n_samples=400, noise=0.4)
y[y==0] = -1
weak_pred = DiskLearner(.5)
weak_pred.fit(X,y)
boosted_pred = DiskBooster(150, .5)
boosted_pred.fit(X,y)
fig = plt.figure(figsize=(16,8))
xlim = [-1.5, 2.5]
ylim = [-2, 2]
ax = fig.add_subplot(1,2,1)
ax.set_title('weak predictor')
ax.set_xlim(xlim)
ax.set_ylim(ylim)
ax.set_aspect('equal')
plot_samples(ax, X, y)
plot_partition(ax, weak_pred, xlim, ylim, [(.75, .75, 1.), (1., .75, .75)])
ax = fig.add_subplot(1,2,2)
ax.set_title('boosted predictor')
ax.set_xlim(xlim)
ax.set_ylim(ylim)
ax.set_aspect('equal')
plot_samples(ax, X, y)
plot_partition(ax, boosted_pred, xlim, ylim, [(.75, .75, 1.), (1., .75, .75)])
plt.savefig('disk-boosting.png')
plt.show()
# Let us show the evolution of boosting.
plt.close(fig)
print()
print('making movies...')
print()
extra_frame_nb = 10
bounds = [1]*extra_frame_nb + [i for i in range(2, len(boosted_pred.preds))] + [len(boosted_pred.preds)]*extra_frame_nb
frame_id = 0
for bound in bounds:
fig = plt.figure(figsize=(8,8))
ax = fig.gca()
ax.set_xlim(xlim)
ax.set_ylim(ylim)
ax.set_aspect('equal')
plot_samples(ax, X, y)
plot_unthresholded_values(ax, boosted_pred, xlim, ylim, bound)
fname = 'frame-{:06d}.png'.format(frame_id)
plt.savefig(fname)
print('{} generated'.format(fname))
frame_id += 1
plt.close(fig)
os.system('ffmpeg -r 10 -i frame-%06d.png -b:v 10M -r 10 disk-boosting.ogv')
Hervé Frezza-Buet,